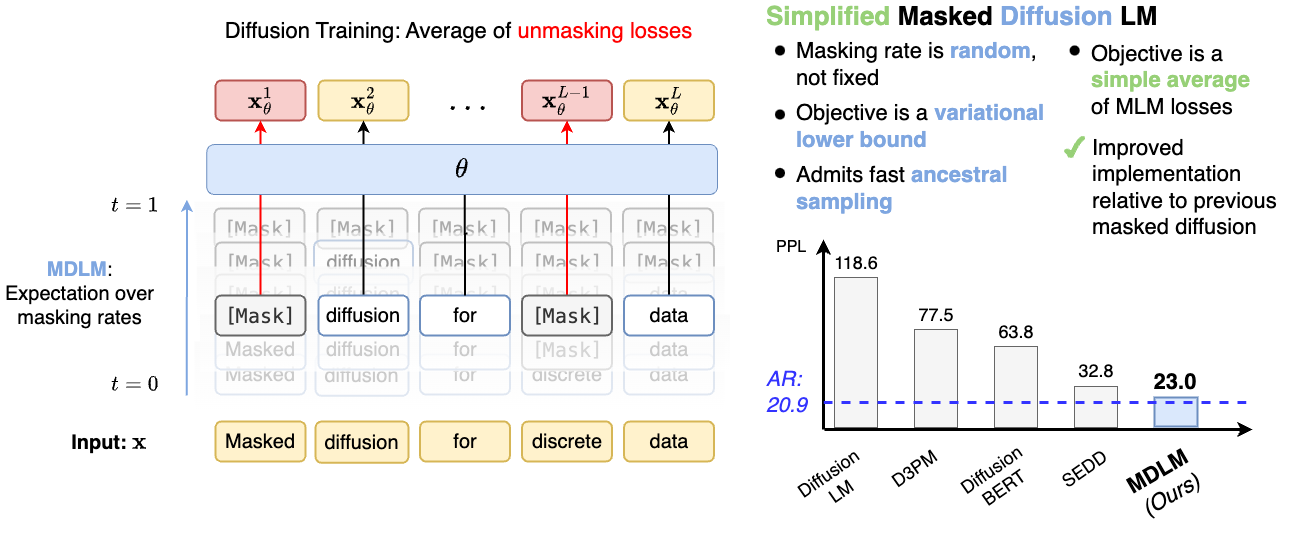
Simple Masked Diffusion Models
While previous work on discrete diffusion supports general forward processes (e.g., general \(Q_t\) in
D3PM), absorbing state (i.e., masking) diffusion consistently achieves the best performance.
In this work, instead of supporting general noise processes, we focus on masking and derive tight
Rao-Blackwellized objectives that outperform general approaches and do not require CTMC theory (for ex. SEDD).
We denote our
overall approach as Masked Diffusion Language Models (MDLM).
Interpolating Masked Diffusion
We forcus on forward processes q that interpolate between clean data \(\mathbf{x} \in \mathcal{V}\),
where \(\mathcal{V}\) is a set of all one-hot vectors, and a target
distribution \(\text{Cat}(.; \boldsymbol{\mathit{\pi}})\). This approach is a direct extention of Gaussian diffusion where the intermediate sample interpolates between the clean data and white noise. The \(q\) defines a sequence
of increasingly noisy latent variables \(\mathbf{z}_t \in \mathcal{V}\), where the time step \(t\) runs from \(t = 0\) (least noisy) to \(t = 1\)
(most noisy).
The marginal of \(\mathbf{z}_t\) conditioned on \(\mathbf{x}\) at time \(t\) is given by
\(q(\mathbf{z}_t|x) = \text{Cat}(\mathbf{z}_t;\alpha_t \mathbf{x}+(1 - \alpha_t) \boldsymbol{\mathit{\pi}})\),
where \(\alpha_t \in [0, 1]\) is a strictly decreasing function in t, with \(\alpha_{t=0} \approx 0\) and \(\alpha_{t=1} \approx 1\).
In absorbing state diffusion, we set \(\boldsymbol{\mathit{\pi}} = \mathbf{m}\) where \(\mathbf{m} \in \mathcal{V}\) and \(\mathbf{m}_K=1\), with \(K^\text{th}\)category representing the special masked token, [MASK].
Reverse process
The specific parameterization for \(p_\theta(\mathbf{z}_s | \mathbf{z}_t)\) with \(0 \leq s < t \leq 1\) that we use is:
\begin{align}\label{eqn:approx_posterior}
p_\theta(\mathbf{z}_s | \mathbf{z}_t) =
q(\mathbf{z}_s | \mathbf{z}_t, \mathbf{x} = \mathbf {x}_\theta (\mathbf{z}_t, t)) =
\begin{cases}
\text{Cat} (\mathbf{z}_s; \mathbf{z}_t), & \mathbf{z}_t \neq \mathbf{m}, \\
\text{Cat} \left( \mathbf{z}_s; \frac{
(1 - \alpha_s)\mathbf{m} + (\alpha_s - \alpha_t) \mathbf{x}_\theta (\mathbf{z}_t, t)}{1 - \alpha_t}\right). & \mathbf{z}_t= \mathbf{m},
\end{cases}
\end{align}
Furthermore, we induce 2 key properties of the absorbing state diffusion process into our denoising
model, \( \mathbf{x}_\theta (\mathbf{z}_t, t): \mathcal{V} \times [0, 1] \rightarrow \Delta^{K}\), where \(\Delta^{K}\) denotes the \(K\)-simplex:
-
Zero Masking Probabilities: First, notice that by definition, \( \langle \mathbf{x}, \mathbf{m} \rangle = 0 \).
For this reason, we design the denoising network such that
\( \langle \mathbf{x}_\theta (\mathbf{z}_t,t),\mathbf{m} \rangle = 0 \), i.e., we substitute the logit index corresponding to the [MASK] token with \(-\infty\).
-
Carry-Over Unmasking: Second, if \( \mathbf{z}_t \) is unmasked, then we desire \( \mathbf{x}_\theta (\mathbf{z}_t, t) = \mathbf{z}_t \), i.e., unmasked latents are "carried over". We accomplish this by substituting the output of our network to simply copy unmasked inputs.
As discussed in the paper, each of these properties plays a crucial role simplifying the Diffusion objetive. We implement these as substitutions to the output of \(\mathbf{x}_\theta (\mathbf{z}_t, t)\), hence we call our parameterization SUBS.
Loss
For a sequence \(\mathbf{x}^{1: L}\) of length \(L\), SUBS parameterization simplifies the Negative Evidence Lower Bound (NELBO) to the following:
\begin{align}
\mathcal{L}_{\text{NELBO}}^\infty = \mathbb{E}_{q}\int_{t=0}^{t=1} \frac{\alpha_{t}'}{1 - \alpha_t} \sum_{\ell = 1}^{L} \log \langle \mathbf {x}_\theta^\ell(\mathbf{z}_t), \mathbf{x}^\ell \rangle \text{d} t
\end{align}
where \(\alpha_{t}'\) denotes the time derivative of \(\alpha_{t}\). As shown in the table below, MDLM outperforms the previous diffusion models and nearly matches the performance of AR models in text generation on the LM1B dataset.
Test perplexities (PPL; ↓) on LM1B. †. Best diffusion value is bolded.
|
|
Parameters |
PPL (↓) |
| Autoregressive |
Transformer-X Base |
0.46B |
23.5 |
| OmniNetT |
100M |
21.5 |
| Diffusion |
BERT-Mouth |
110M |
≤142.89 |
| D3PM (absorb) |
70M |
≤77.50 |
| Diffusion-LM |
80M |
≤118.62 |
| DiffusionBert |
110M |
≤63.78 |
| SEDD |
110M |
≤32.79 |
| Autoregressive (Retrained) |
Transformer (33B tokens) |
110M |
22.32 |
| Transformer (327B tokens) |
20.86 |
| Diffusion (Ours) |
MDLM (33B tokens) |
110M |
≤27.04 |
| MDLM (327B tokens) |
≤23.00 |
We also explore models' ability to generalize by taking models trained on OWT and evaluating how well they model unseen datasets.
We compare the zero-shot perplexities of MDLM with SEDD and an AR Transformer language model on the validation splits of Penn Tree Bank (PTB), Wikitext, LM1B, Lambada, AG News, and Scientific Papers (Pubmed and Arxiv subsets).
MDLM consistently outperforms SEDD.
In some cases, e.g., for Lambada and Scientific Papers, MDLM attains better perplexity than AR.
We hypothesize that these datasets are farther from OWT, and that diffusion models may be more robust to out-of-domain evaluation due to the unmasking-based objective.
Zero-shot validation perplexities ( ↓) of models trained for 524B tokens on OpenWebText.
All perplexities for diffusion models are upper bounds.
|
PTB |
Wikitext |
LM1B |
Lambada |
AG News |
Pubmed |
Arxiv |
| AR (Retrained) |
82.05 |
25.75 |
51.25 |
51.28 |
52.09 |
49.01 |
41.73 |
| SEDD (Retrained) |
100.09 |
34.28 |
68.20 |
49.86 |
62.09 |
44.53 |
38.48 |
| MDLM (Ours) |
95.26 |
32.83 |
67.01 |
47.52 |
61.15 |
41.89 |
37.37 |
Training Considerations for Masked Diffusion
One of the key contributions of our work is a well-engineered implementation of masked diffusion
models. Our experiments demonstrate that these improvements greatly boost performance even for
methods previously thought to perform poorly, e.g., D3PM . Below we briefly summarize these
implementation details.
- We find that tokenization is critical to performance. Small vocabularies,
such as the 8k vocabulary in D3PM, result in longer-range dependencies that decrease the
performance of both diffusion and AR models.
- By focusing on masked diffusion, we
are able to provide a numerically stable implementation of the objective function. Namely, since
previous formulations of discrete diffusion were constructed to accommodate a wide range of limiting
distributions, the objective was implemented by materializing the full transition matrices \(Q_t\) and
posterior probabilities. In contrast, we evaluate
\(\text{D}_{\text{KL}}[q(\mathbf{z}_s | \mathbf{z}_t,\mathbf{x}) \| p_\theta (\mathbf{z}_s | \mathbf{z}_t)]\) by examining only the
masked token indices rather than comparing the full true and approximate posterior distributions.
- Furthermore, we modernize the architecture for the denoising network relative to D3PM. In lieu
of the T5 architecture used in D3PM, we use the diffusion transformer (DiT), which integrates time step conditioning into a standard encoder-only transformer and uses rotary positional embeddings.
- In addition, we implement a low-discrepancy sampler
that reduces the variance of the ELBO, similar to Kingma et al. and draws correlated samples
\(t \in [0, 1]\) rather than performing i.i.d. sampling along the batch dimension.
 Colab
Colab